

15 janvier 2014
3
15
/01
/janvier
/2014
11:21
Nouvelle année, nouvelles résolutions.
La première : coder un échiquier pour jouer sous SQL*Plus.
J'ai posté le script complet ici :
1) Le modèle de données
Le modèle de données est simple : c'est la liste des coups joués, ni plus ni moins.
CREATE TABLE cs_mouv (
x number,
y number,
x_dest number,
y_dest number,
n_mouv number,
piece char(1),
col char(1),
move_str varchar2(10),
fic char(1) default 'N'
);
Pour cela :
- on enregistre la case de départ (x, y), la case d'arrivée (x_dest, y_dest), la pièce et sa couleur
- le numéro du coup (n_mouv)
- Le flag "fic", comme fictif, permet de décomposer les coups spéciaux en plusieurs mouvements.
Comme le roque, la prise en passant, la promotion...
- Le "move_str" ne sert qu'à conserver la châne saisie par l'utilisateur, pour des raisons pratiques.
2) Reconstituer la position à partir de la liste des coups
Quand on a la liste des coups, et si on n'est pas complètement stupide, on peut en déduire la position.
CREATE OR REPLACE VIEW pieces AS
SELECT x_dest x, y_dest y, max(piece) keep(dense_rank last order by n_mouv) piece
, max(col) keep(dense_rank last order by n_mouv) col
FROM (
SELECT x_dest, y_dest, n_mouv
, piece
, col
FROM cs_mouv
WHERE x_dest IS NOT NULL
UNION ALL
SELECT x, y, n_mouv
, null
, null
FROM cs_mouv
)
GROUP BY x_dest, y_dest
/
Il s'agit là de se baser sur les cases de l'échiquier, et de chercher quelle est la pièce qui s'y situe actuellement.
La première partie de l'UNION ALL liste les pièces arrivant sur une case donnée, la deuxième partie les cases abandonnées... on retient dans tout ça la pièces correspondant au plus récent numéro de coup pour chaque case.
3) Afficher la position
La procédure pkg_csboard.display affiche la position actuelle. La vue "pieces" donnant déjà toutes les positions, il s'agit juste de metre en forme le résultat.
Le paramètre en entrée permet d'orienter l'affichage (noirs ou blancs) par l'inversion du système de coordonnées.
A noter que par défaut, SQL*Plus justifie les "leading spaces" (les premiers espaces à gauche), ce qui fout en l'air les efforts de mise en forme.
Pour empêcher cela, il faut entrer l'option :
SET SERVEROUTPUT ON FORMAT WRAPPED
4) Initialiser l'échiquier
La procécdure pkg_csboard.init supprime la liste des coups, puis insère toutes les pièces dans leur position initiale.

5) Jouer des coups
La procédure cs_move prend en paramètre la chaîne de caractères représentant la position initiale et la destination de la pièce à déplacer, contrôle la validité du coup, l'exécute, puis affiche la position :
SQL> exec pkg_csboard.csmove('e2e4');

La sous-procédure parse_move vérifie la validité du coup, et retourne le type de coup effectué (erreur, coup normal, petit roque, ...). J'ai pas eu la motivation d'implémenter la prise en passant et la promotion, mais ça doit pas être bien compliqué.
La sous-procédure exec_move est appelée ensuite pour effectuer l'insertion effective.
SQL> exec pkg_csboard.csmove('oo');
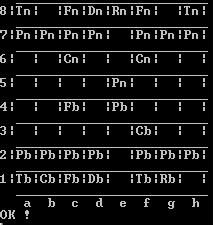
6) Afficher la liste des coups.
C'est la procédure display_list. J'aurais pu m'amuser à mettre des tirets, mais j'avais la flemme.
SQL> exec pkg_csboard.display_list;
1. e2e4 e7e5
2. g1f3 b8c6
3. f1c4 g8f6
4. oo
7) Annuler des coups
Comme on a la liste des coups, ce n'est pas bien compliqué non plus de revenir en arrière...
La procédure cancel_move supprime le nombre de coups passés en paramètres, en rassemblant au préalable les coups fictifs avec leur coup réel associé.
SQL> exec pkg_csboard.cancel_move(2);

Voilà, il resterait encore plein de choses à faire :
- implémenter les coups spéciaux manquants
- vérifier la validité des coups
- insérer le concept de partie
- utiliser si possibles des queues pour que deux personnes puissent jouer "sur le réseau"
- encapsuler ça dans du shell pour pouvoir faire des boucles
- ...
Mais je préfère faire les choses à moitié, c'est mieux.
Partager cet article


